Training details
- Trained by communication rounds of 500 (100 for SVHN)
- 100 clients, fraction rate of 0.1 each round (i.e., 10 clients each round)
- Local batch size of 32 and local epochs of 5
- Optimizer: SGD with learning rate of 0.1 without momentum and weight decay
-
Learning rate decreased by a factor of 0.1 at halfway point and 3/4 of the total communication rounds
- System heterogeneity: each client trained one of the submodels in each iteration.
- One with five submodels (Ns=5, where γ = [γ1, γ2, γ3, γ4, γ5] = [0.2, 0.4, 0.6, 0.8, 1]).
- The clients were evenly distributed across tiers corresponding to the number of submodels.
- A client in tier x selects a submodel uniformly from the range [max(γ1, γx-2), min(γx+2, γ5)] during each iteration due to dynamically varying system availability.
- One with five submodels (Ns=5, where γ = [γ1, γ2, γ3, γ4, γ5] = [0.2, 0.4, 0.6, 0.8, 1]).
- Statistical heterogeneity: label distribution skew following the Dirichlet distribution with a concentration parameter of 0.5.
Details on architectures of submodels
[Example]
Please note that the widthwise scaling (𝛾W) is uniformly applied across all blocks.
Consider Model index 1 and 2 in NeFL-D on ResNet18. The architecture is illustrated as follows:
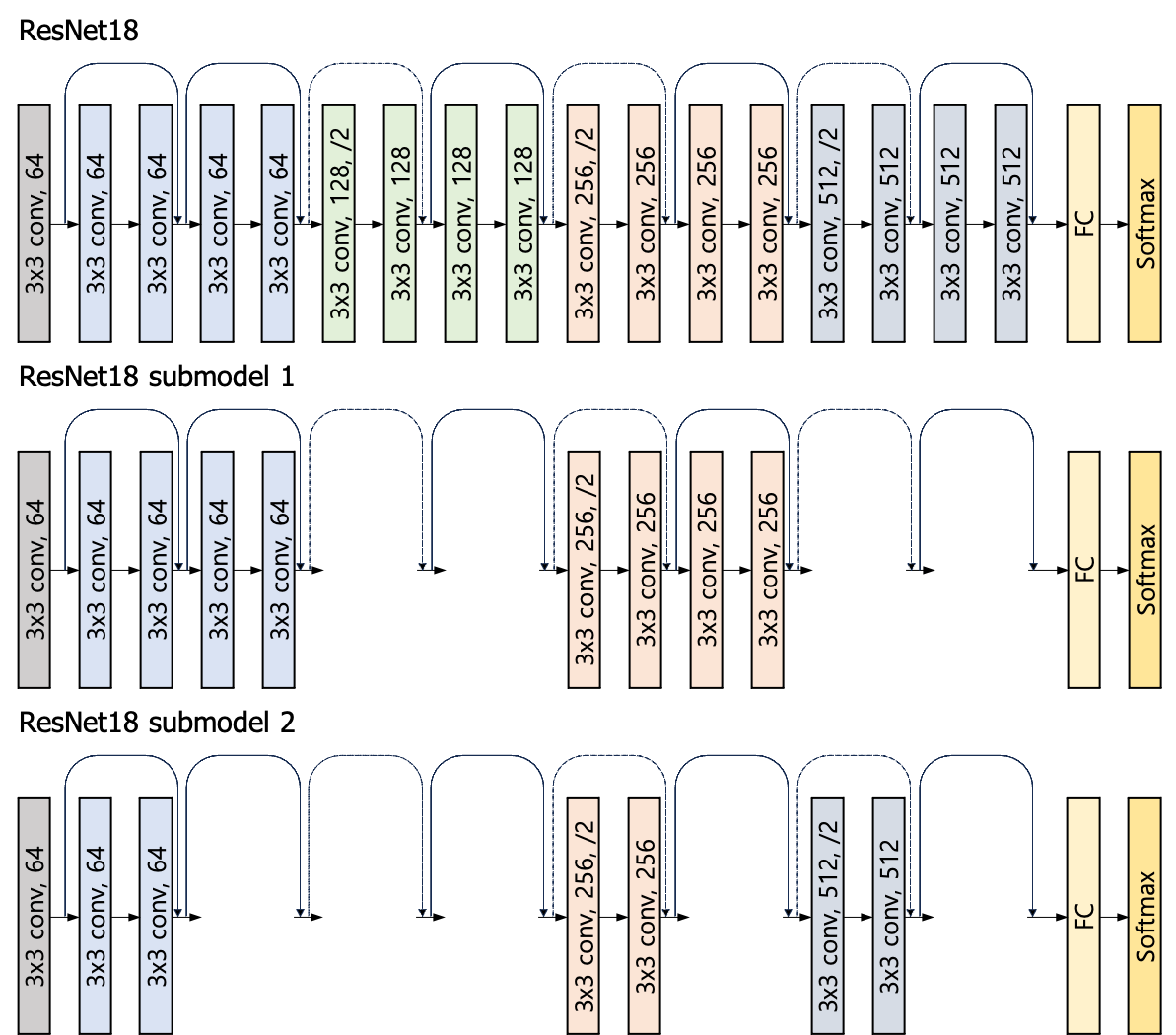
ResNet18
Details of 𝛾 of NeFL-D on ResNet18
| Model index | Model size 𝛾 | 𝛾W | 𝛾D | NeFL-D (ResNet18) | |||
|---|---|---|---|---|---|---|---|
| Layer 1 (64) | Layer 2 (128) | Layer3 (256) | Layer 4 (512) | ||||
| 1 | 0.20 | 1 | 0.20 | 1,1 | 0,0 | 1,1 | 0,0 |
| 2 | 0.38 | 1 | 0.38 | 1,0 | 0,0 | 1,0 | 1,0 |
| 3 | 0.57 | 1 | 0.57 | 1,1 | 1,1 | 1,1 | 1,0 |
| 4 | 0.81 | 1 | 0.81 | 1,0 | 1,1 | 0,0 | 1,1 |
| 5 | 1 | 1 | 1 | 1,1 | 1,1 | 1,1 | 1,1 |
Details of 𝛾 of NeFL-WD on ResNet18
| Model index | Model size 𝛾 | 𝛾W | 𝛾D | NeFL-WD (ResNet18) | |||
|---|---|---|---|---|---|---|---|
| Layer 1 (64) | Layer 2 (128) | Layer3 (256) | Layer 4 (512) | ||||
| 1 | 0.20 | 0.34 | 0.58 | 1,1 | 1,1 | 1,1 | 1,0 |
| 2 | 0.4 | 0.4 | 1 | 1,1 | 1,1 | 1,1 | 1,1 |
| 3 | 0.6 | 0.6 | 1 | 1,1 | 1,1 | 1,1 | 1,1 |
| 4 | 0.8 | 0.8 | 1 | 1,1 | 1,1 | 1,1 | 1,1 |
| 5 | 1 | 1 | 1 | 1,1 | 1,1 | 1,1 | 1,1 |
ResNet34
Details of 𝛾 of NeFL-D on ResNet34
| Model index | Model size 𝛾 | 𝛾W | 𝛾D | NeFL-D (ResNet34) | |||
|---|---|---|---|---|---|---|---|
| Layer 1 (64) | Layer 2 (128) | Layer 3 (256) | Layer 4 (512) | ||||
| 1 | 0.23 | 1 | 0.23 | 1,0,0 | 1,0,0,0 | 1,0,0,0,0,0 | 1,0,0 |
| 2 | 0.39 | 1 | 0.39 | 1,1,1 | 1,1,1,1 | 1,1,0,0,0,1 | 1,0,0 |
| 3 | 0.61 | 1 | 0.61 | 1,1,1 | 1,1,1,1 | 1,1,0,0,0,1 | 1,0,1 |
| 4 | 0.81 | 1 | 0.81 | 1,1,1 | 1,0,0,1 | 1,1,0,0,0,1 | 1,1,1 |
| 5 | 1 | 1 | 1 | 1,1,1 | 1,1,1,1 | 1,1,1,1,1,1 | 1,1,1 |
Details of 𝛾 of NeFL-WD on ResNet34
| Model index | Model size 𝛾 | 𝛾W | 𝛾D | NeFL-WD (ResNet34) | |||
|---|---|---|---|---|---|---|---|
| Layer 1 (64) | Layer 2 (128) | Layer 3 (256) | Layer 4 (512) | ||||
| 1 | 0.20 | 0.38 | 0.53 | 1,1,1 | 1,0,0,1 | 1,0,0,0,0,1 | 1,0,1 |
| 2 | 0.40 | 0.63 | 0.64 | 1,1,1 | 1,0,0,1 | 1,1,1,0,0,1 | 1,0,1 |
| 3 | 0.60 | 0.77 | 0.78 | 1,1,1 | 1,1,1,1 | 1,1,1,1,0,1 | 1,0,1 |
| 4 | 0.80 | 0.90 | 0.89 | 1,1,1 | 1,1,1,1 | 1,1,1,0,0,1 | 1,1,1 |
| 5 | 1 | 1 | 1 | 1,1,1 | 1,1,1,1 | 1,1,1,1,1,1 | 1,1,1 |
ResNet56
Details of 𝛾 of NeFL-D on ResNet56
| Model index | Model size 𝛾 | 𝛾W | 𝛾D | NeFL-D (ResNet56) | ||
|---|---|---|---|---|---|---|
| Layer 1 (16) | Layer 2 (32) | Layer 3 (64) | ||||
| 1 | 0.2 | 1 | 0.2 | 1, 1, 0, 0, 0, 0, 0, 0, 0 | 1, 1, 0, 0, 0, 0, 0, 0, 0 | 1, 1, 0, 0, 0, 0, 0, 0, 0 |
| 2 | 0.4 | 1 | 0.4 | 1, 1, 1, 0, 0, 0, 0, 0, 0 | 1, 1, 1, 0, 0, 0, 0, 0, 0 | 1, 1, 1, 1, 0, 0, 0, 0, 0 |
| 3 | 0.6 | 1 | 0.6 | 1, 1, 1, 1, 0, 0, 0, 0, 0 | 1, 1, 1, 1, 0, 0, 0, 0, 0 | 1, 1, 1, 1, 1, 1, 0, 0, 0 |
| 4 | 0.8 | 1 | 0.8 | 1, 1, 1, 1, 1, 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 0 | 1, 1, 1, 1, 1, 1, 1, 0, 0 |
| 5 | 1 | 1 | 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1 |
Details of 𝛾 of NeFL-WD on ResNet56
| Model index | Model size 𝛾 | 𝛾W | 𝛾D | NeFL-WD (ResNet56) | ||
|---|---|---|---|---|---|---|
| Layer 1 (16) | Layer 2 (32) | Layer 3 (64) | ||||
| 1 | 0.2 | 0.46 | 0.43 | 1, 1, 1, 1, 0, 0, 0, 0, 0 | 1, 1, 1, 1, 0, 0, 0, 0, 0 | 1, 1, 1, 1, 0, 0, 0, 0, 0 |
| 2 | 0.4 | 0.61 | 0.66 | 1, 1, 1, 1, 1, 1, 0, 0, 0 | 1, 1, 1, 1, 1, 1, 0, 0, 0 | 1, 1, 1, 1, 1, 1, 0, 0, 0 |
| 3 | 0.6 | 0.77 | 0.77 | 1, 1, 1, 1, 1, 1, 1, 0, 0 | 1, 1, 1, 1, 1, 1, 1, 0, 0 | 1, 1, 1, 1, 1, 1, 1, 0, 0 |
| 4 | 0.8 | 0.90 | 89 | 1, 1, 1, 1, 1, 1, 1, 1, 0 | 1, 1, 1, 1, 1, 1, 1, 1, 0 | 1, 1, 1, 1, 1, 1, 1, 1, 0 |
| 5 | 1 | 1 | 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1 |
ReNet110
Details of 𝛾 of NeFL-D on ResNet110
| Model index | Model size 𝛾 | 𝛾W | 𝛾D | NeFL-D (ResNet110) | ||
|---|---|---|---|---|---|---|
| Layer 1 (16) | Layer 2 (32) | Layer 3 (64) | ||||
| 1 | 0.2 | 1 | 0.20 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0 | 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 | 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 |
| 2 | 0.4 | 1 | 0.40 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0 | 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 | 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 |
| 3 | 0.6 | 1 | 0.60 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0 |
| 4 | 0.8 | 1 | 0.80 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0 |
| 5 | 1 | 1 | 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 |
Details of 𝛾 of NeFL-WD on ResNet110
| Model index | Model size 𝛾 | 𝛾W | 𝛾D | NeFL-WD (ResNet110) | ||
|---|---|---|---|---|---|---|
| Layer 1 (16) | Layer 2 (32) | Layer 3 (64) | ||||
| 1 | 0.2 | 0.46 | 0.44 | 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 | 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 | 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 |
| 2 | 0.4 | 0.60 | 0.66 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1 |
| 3 | 0.6 | 0.77 | 0.77 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1 |
| 4 | 0.8 | 0.90 | 0.89 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1 |
| 5 | 1 | 1 | 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 |
Wide ResNet
Details of 𝛾 of NeFL on Wide ResNet101_2
| Model index | Model size 𝛾 | 𝛾W | 𝛾D | NeFL-D (Wide ResNet101_2) | |||
|---|---|---|---|---|---|---|---|
| Layer 1 (128) | Layer 2 (256) | Layer 3 (512) | Layer 4 (1024) | ||||
| 1 | 0.5 | 1 | 0.51 | 1, 1, 1 | 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 | 1, 1, 0 |
| 2 | 0.75 | 1 | 0.75 | 1, 1, 1 | 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0 | 1, 1, 1 |
| 3 | 1 | 1 | 1 | 1, 1, 1 | 1, 1, 1, 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 | 1, 1, 1 |
ViT-B/16
| Model index | Model size 𝛾 | 𝛾W | 𝛾D | NeFL-D (ViT-B/16) |
|---|---|---|---|---|
| Block | ||||
| 1 | 0.5 | 1 | 0.50 | 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0 |
| 2 | 0.75 | 1 | 0.75 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0 |
| 3 | 1 | 1 | 1 | 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 |
Pre-trained models (trained on ImageNet-1k)
ResNet18/34
- Trained by epochs of 90, batch size of 32
- Optimizer: SGD with learning rate of 0.1, momentum of 0.9, and weight decay of 0.0001
- Learning rate decreased by a factor of 0.1 every 30 epochs
Wide ResNet101_2
- Trained by epochs of 90, batch size of 32
- Optimizer: SGD with learning rate of 0.1, momentum of 0.9, and weight decay of 0.0001
- Learning scheduler: Cosine learning rate with warming up restarts for 256 epochs
ViT-B/16
- Trained by epochs of 300, batch size of 512
- Optimizer: AdamW with learning rate of 0.003 and weight decay of 0.3
- Learning scheduler: Cosine annealing after linear warmup method with decay of 0.033 for 30 epochs
- Augmentation:
- Random augmentation
- Random mixup with alpha=0.2
- Cutmix with alpha=1
- Repeated augmentation
- Label smoothing of 0.11
- Gradient norm clipping to 1
- Model exponential moving average (EMA)
Comparing Wide ResNet101_2 & ViT-B/16
Training details
- Trained by communication rounds of 100
- 10 clients, fraction rate of 1 each round (i.e., 10 clients each round)
- Local batch size of 32 and local epochs of 1
- Optimizer: SGD with learning rate of 0.1 without momentum and weight decay
- Cosine annealing learning rate scheduling with 500 steps of warmup and an initial learning rate of 0.03
- Input images are resized to a size of 256x256 and randomly cropped to a size of 224x224 with a padding size of 28 28